Project
Prisoner’s Dilemma: Algorithmic Modeling & Simulation Research Study
Project Overview
Simulating and researching the prisoner’s dilemma study. Based on algorithmic design of different approaches to the game at hand, scores across 10,000+ games of the Prisoner’s Dilemma will return different results each time the game is simulated.
You can learn more in this paper, aptly titled: Prisoner’s Dilemma first published in September 1997, last revised April 2019 in the Stanford Encyclopedia of Philosophy. I have included a key excerpt from the paper below that summarizes the core philosophical concepts and challenges posed by the Prisoner’s Dilemma:
Summary Excerpt
“The “dilemma” faced by the prisoners here is that, whatever the other does, each is better off confessing than remaining silent. But the outcome obtained when both confess is worse for each than the outcome they would have obtained had both remained silent. A common view is that the puzzle illustrates a conflict between individual and group rationality. A group whose members pursue rational self-interest may all end up worse off than a group whose members act contrary to rational self-interest. More generally, if the payoffs are not assumed to represent self-interest, a group whose members rationally pursue any goals may all meet less success than if they had not rationally pursued their goals individually. A closely related view is that the prisoner’s dilemma game and its multi-player generalizations model familiar situations in which it is difficult to get rational, selfish agents to cooperate for their common good.“
Click Below to Continue Reading
Axelrod’s Tournament
Axelrod’s 1980 Prisoner’s Dilemma Tournament tested a variety of pre-programmed strategies including: Always Defect, Always Cooperate, Random, and Tit for Tat. The tournament was a series of matches where each aforementioned algorithm (devised as a program) would compete against each other repeatedly. Tit for Tat, the strategy designed to mirror its opponent’s previous move, emerged as the eventual tournament winner by taking a level-headed approach of balancing retaliation and cooperation. Below I have embedded a core webpage I referred to during the research stage of my project.
Roberts, E. (1998–1999). Axelrod’s tournament. Stanford University. https://cs.stanford.edu/people/eroberts/courses/soco/projects/1998-99/game-theory/axelrod.html
Algorithms
Algorithmic Analysis of of Existing Strategies
In recreating Axelrod’s tournament, this project began by implementing the foundational strategies that defined the original study. These served as the control group for the simulation:
-
Always Defect: A purely selfish algorithm that never cooperates. It exploits friendly strategies but fails miserably against itself.
-
Always Cooperate: The altruist. It maximizes the group score when paired with other cooperators but is easily taken advantage of by defectors.
-
Random: serves as a baseline for “zero intelligence.” It acts without memory or plan, cooperating or defecting with a 50/50 probability.
-
Tit for Tat (TFT): The historical champion. It begins by cooperating, then simply copies the opponent’s last move. It is defined by being nice (never defects first), retaliatory (punishes defection immediately), and forgiving (returns to cooperation if the opponent does).
Designing New Algorithms / Strategies
Beyond the classics, this project explored custom algorithmic designs to test the limits of TFT. The development phase involved creating variations such as:
-
The Grudger: Cooperates until the opponent defects once, then defects forever. (A less forgiving variant of TFT).
-
Opportunistic TFT: Plays like Tit for Tat but will occasionally defect against a “weak” opponent (like Always Cooperate) to maximize individual gain.
-
Probing Strategies: Algorithms that defect early to test the opponent’s reaction, then adjust behavior based on whether the opponent retaliates or submits.
Development
The simulation was built using Python, leveraging its robust libraries for data handling and iterative calculation. The development followed an Object-Oriented approach:
-
PlayerClass: Defined the memory and decision-making logic for each strategy. -
MatchClass: Handled the interaction between two players for a set number of rounds. -
TournamentClass: Managed the round-robin logic, ensuring every algorithm played every other algorithm 10,000+ times to gather statistically significant data.
Cycles & Iterations
The development cycle was iterative. Initial simulations revealed that simple strategies often stuck in loops (e.g., two TFT players cooperating forever). To make the simulation realistic, “noise” was introduced. Noise is a small probability that a player attempts to Cooperate but accidentally Defects (simulating miscommunication). This forced the algorithms to handle error recovery, a critical component of real-world game theory.
Simulation
The core simulation ran over 10,000 iterations of the game. A single game of Prisoner’s Dilemma is interesting, but a “supergame” (iterated dilemma) reveals the true nature of the strategies.
-
Input: A pool of 5–10 distinct algorithms.
-
Process: Each algorithm paired with every other algorithm for 200 rounds.
-
Output: Raw score data, defect/cooperate ratios, and accumulated “years in prison” (points inverted).
Data Analysis & Visualization
Plotting using Python
Using Matplotlib and Pandas, the raw simulation data was visualized to identify trends that raw numbers obscured.
-
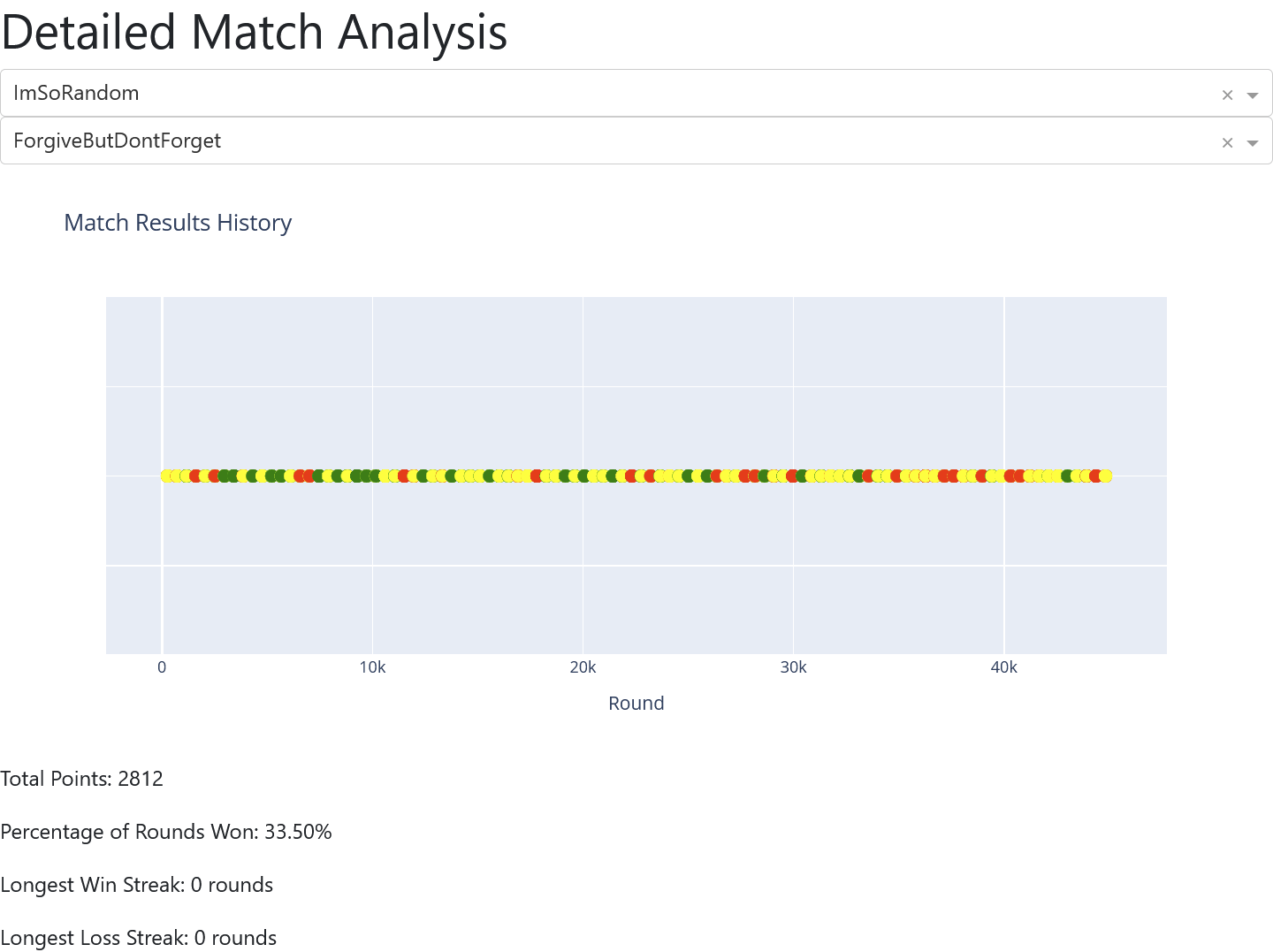
Line Graphs: Showed the cumulative score of strategies over time. Tit for Tat often starts slow but overtakes aggressive strategies in the long run.
-
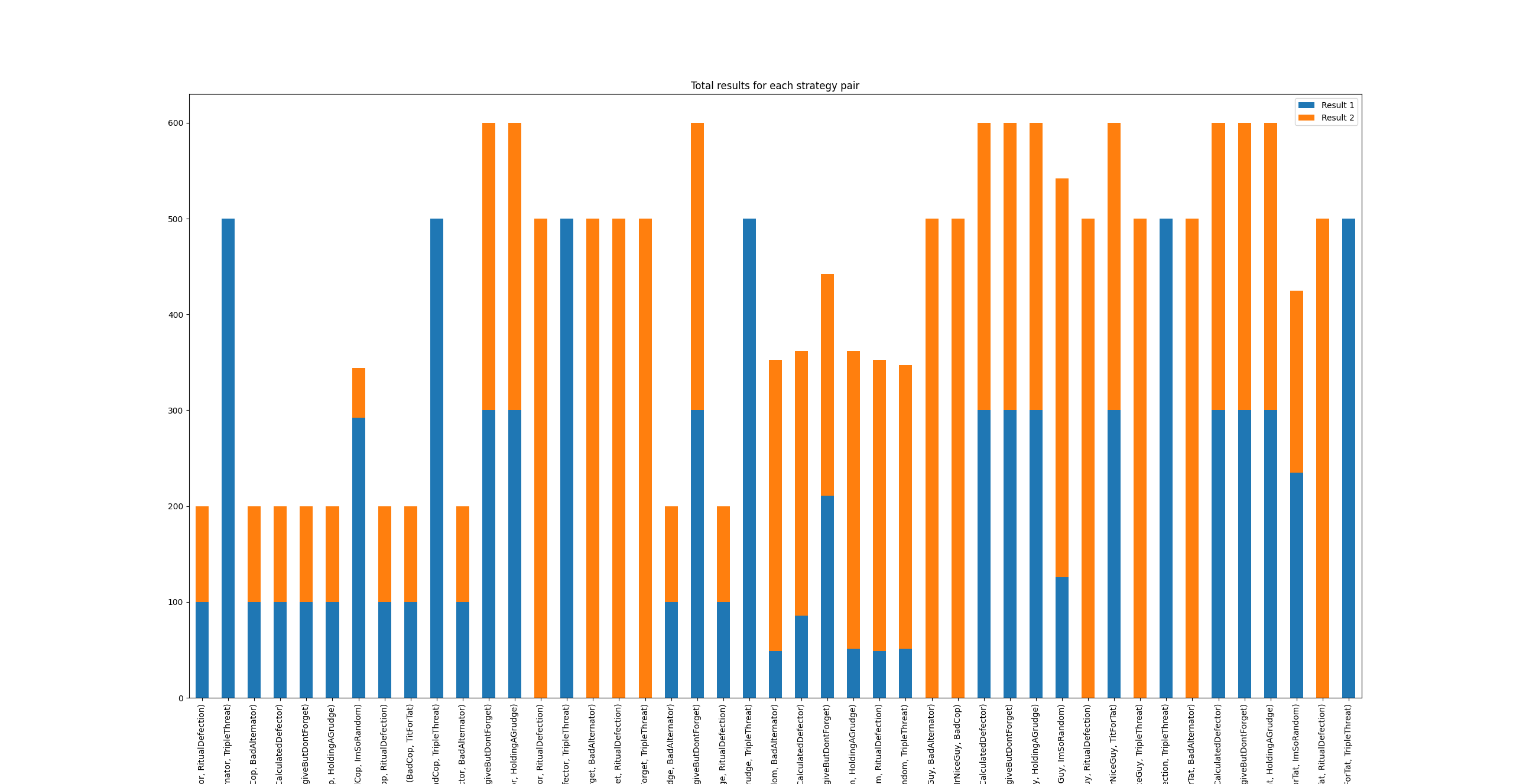
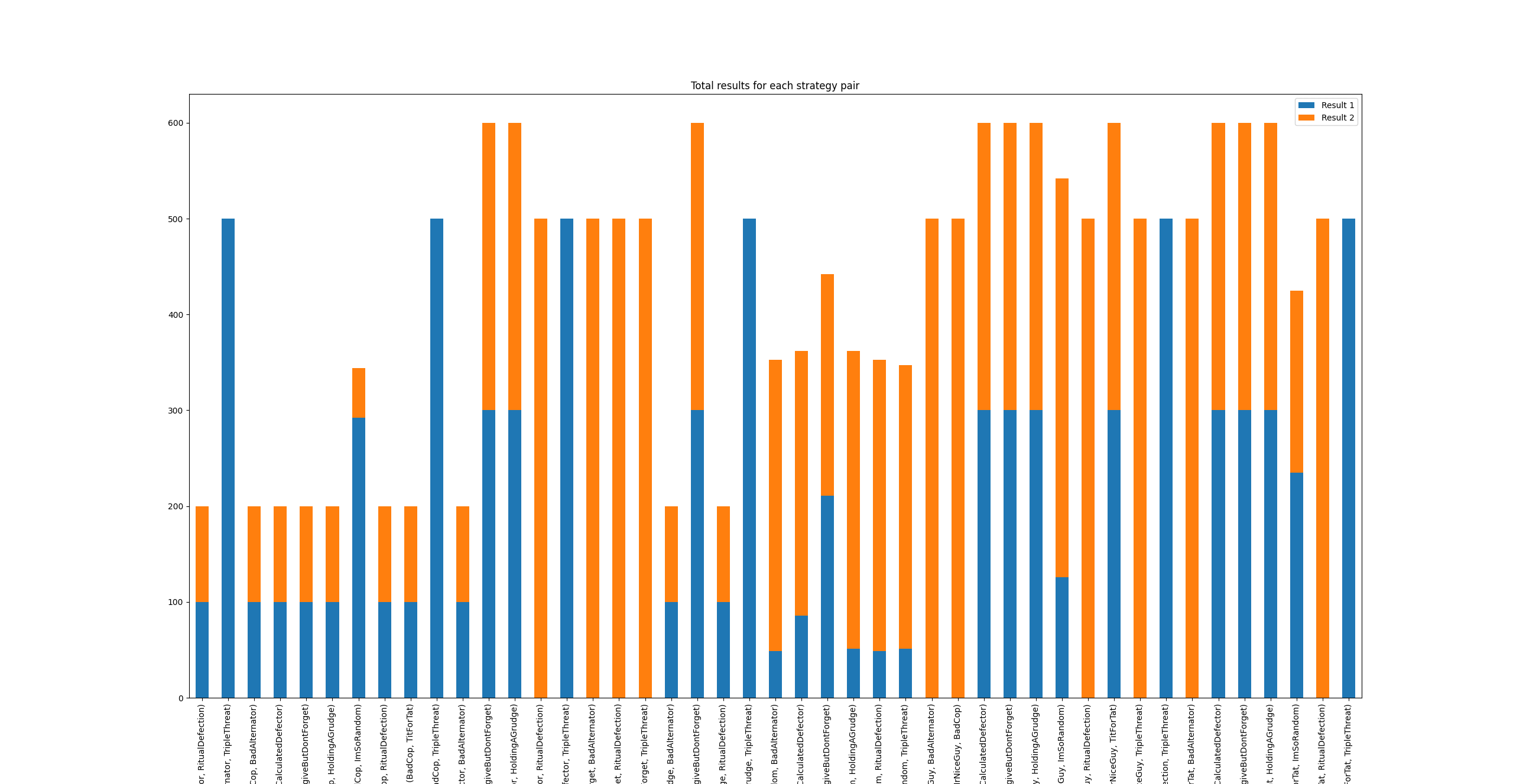
Heatmaps: visualized the “Face-off Matrix,” showing exactly how many points Strategy A took from Strategy B. This revealed that while Always Defect wins individual battles, it loses the war by failing to accumulate high-score cooperative runs.
Game Theory Findings
The Butterfly Effect in Game Theory
One of the most profound findings of this simulation was the sensitivity of the results to initial conditions—the “Butterfly Effect.”
Small Tweaks Lead to Big Changes:
Adjusting the “forgiveness” parameter of a custom algorithm by just 5% (e.g., forgiving a defection 10% of the time vs 15% of the time) could move a strategy from last place to first place..
Uniqueness
As noted in the project title, “No Two Will Ever Be Exactly Alike.” In simulations involving random noise or probabilistic strategies, the simulation history diverges wildly. A single accidental defection in Round 3 can spiral into a “blood feud” of mutual defection that lasts 100 rounds, completely altering the final scores compared to a simulation where that accident didn’t happen.
Project Repository
Explore the full source code, including the Player classes, simulation logic, and visualization scripts on GitHub.